
The Centers for Medicare and Medicaid (CMS) Data Center is bursting at the seams with historical data and continues to process more than one billion claims each year! That is a LOT of data – 30 years of claims history, stored in 2,500 files that add up to 500 terabytes (TB) of data.
Imagine the massive volume of data CMS needs to store. It includes detailed history for adjudicated Medicare claims from 1991 to the present for all inpatient, skilled nursing facility, outpatient, home health, hospice, Durable Medical Equipment (DME) and carrier type claims. Now imagine all that data stored only on tape on the CMS mainframe.
Until recently, that was the case. That outdated system made it tough to get data to researchers and analysts in a timely fashion. But there’s good news: We have migrated the files older than four years to the CMS AWS Cloud for archiving, with over 500TB stored in Amazon S3 and Glacier. Thanks to this migration, CMS is a more agile organization prepared to meet the demands of 21st century healthcare.
Continuous Data Delivery Pipeline: End-to-End Automation
The agency approached us to migrate the data from mainframe to AWS. Our goal was to build a completely automated continuous data delivery pipeline to migrate the data without human intervention. The automated approach will minimize the maintenance in operations to migrate the data in upcoming years.
The automated delivery pipeline in the following diagram lists all the steps within the pipeline to migrate the mainframe data to the destination in AWS Cloud (S3/Glacier). The Tivoli Workload Scheduler (TWS) enables us to establish the rules for the automated data delivery pipeline to refresh the data as often as desired.
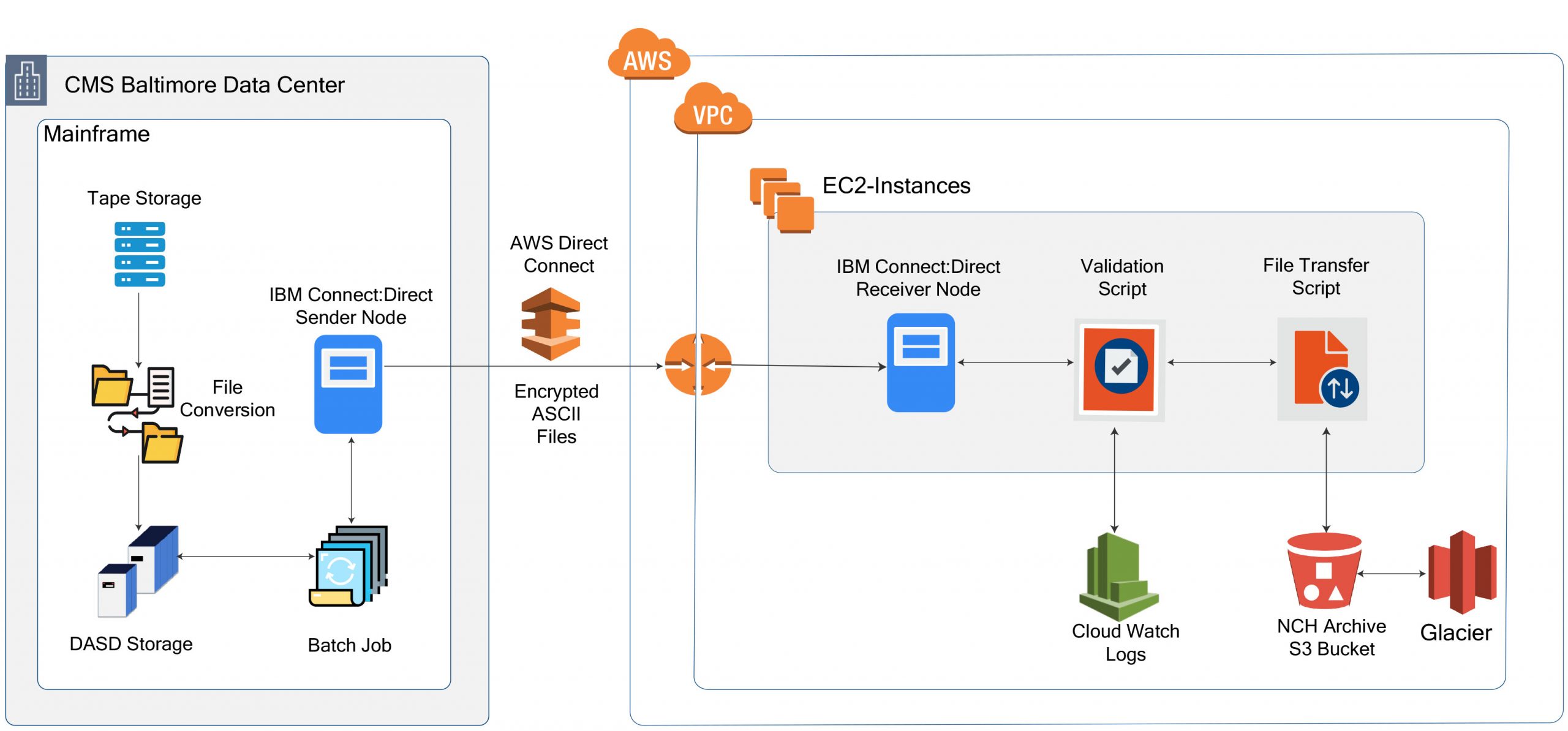
Medicare Data in Cloud – Endless Possibilities
What did CMS gain from this migration? There are two major benefits of housing Medicare data in the cloud:
- A cost savings of approximately 31% on average, including data tiering (S3 vs Glacier) for the Government
- Access to cloud-native analytical tools and technologies that add value for research and analyst stakeholders
- They will be able to process and analyze big data faster, leading to insights that can provide even more value for the agency
- They will realize endless possibilities at their fingertips
Shrinking Data Dissemination from Weeks to Hours
Prior to the cloud migration, accessing data on the mainframe was a long and cumbersome process. Typically, you would need to wait up to two weeks to get access to files. Then, you would need to parse through that data using the limited tools available on the mainframe. Next, you would copy that information into another environment to get what you need.
Today, CMS’s cloud infrastructure dramatically accelerates that process. The archived data in the cloud is available in mere hours rather than the weeks it took to retrieve files from the mainframe.
Claims Data API
Another breakthrough for CMS is that it now has a robust claims data application programming interface (API). This API empowers other computers/systems to access the claims data without a need to understand the complexity of the data.
What are the features of a well-designed API? Robust APIs:
- Provide Simple and easy to comprehend interfaces
- Offer Flexibility of input and output constraints
- Require the least amount of effort for the user to get what they need
Without an API, users download data from cloud storage (AWS S3 and S3/Glacier) to another machine for analysis. These files range in size from 220MB to 1.55TB, which will take significant time to download.
Once downloaded, you will likely realize you will need more than one file to get to what you need (a full year of data requires 100 files!) You will also need a system robust enough to hold and manipulate that amount of data. Then, you will use another application to filter the data to the records (or fields) you need.
Only after jumping through all those hoops can you begin your analysis. To reduce this multi-step burden, we have created an API that can reach into the files stored in AWS and only extract the records you need into a single output file.

The Claims Data API requests the year and claim type. Immediately, the API provides a count of the number of claims from that file for each claim type. Then, the API then triggers a script that will move the file from S3 to EC2 and extracts the records for the claim type(s) requested into a new file. The API then emails the requestor to notify them the extract is ready for download.
In the future, CMS may use the Claims Data API be to perform other common functions such as claims data validation.
Predictive Analytics and Machine Learning
The data we have migrated to the cloud includes vast amounts of longitudinal claims data collected since 1991. It is a gold mine for machine learning. Because it is non-operational data, there is minimal disruption while performing analytics.
A researcher or auditor can have total visibility into a claims record – Beneficiary Profile, Demographics, Provide, Claims Details, etc. Over 400 fields are available!
What’s next for CMS? As a value add, we created a prototype predictive analytics dashboard to summarize key metrics: Year, Claim Type, Total Amount and Total Count. Users can enhance the dashboard to include more metrics such as demographics, health status, and social determinants that will enhance the business value to the agency.
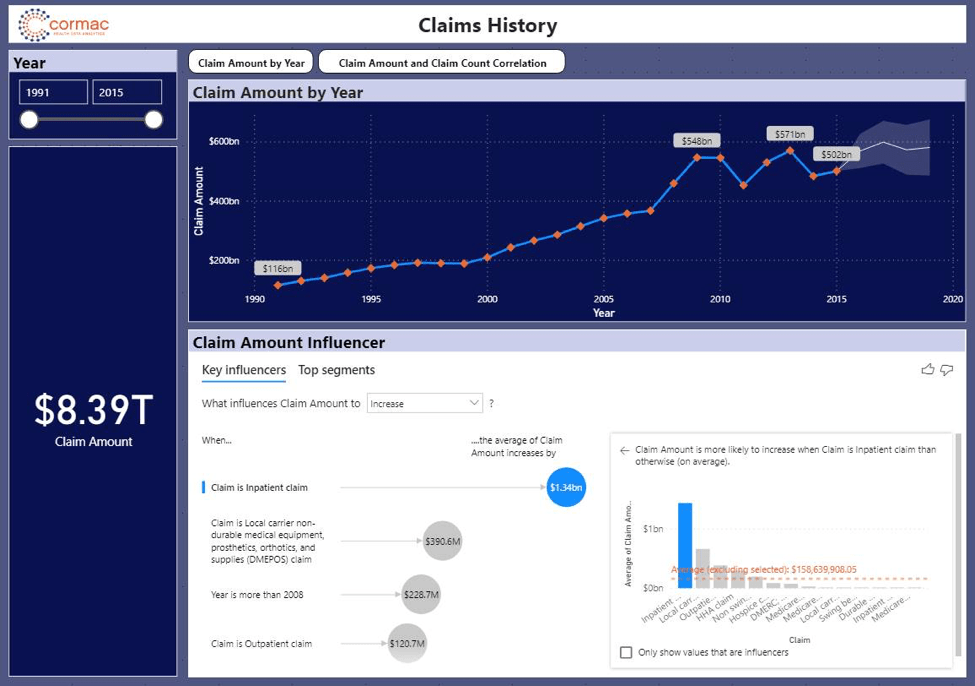
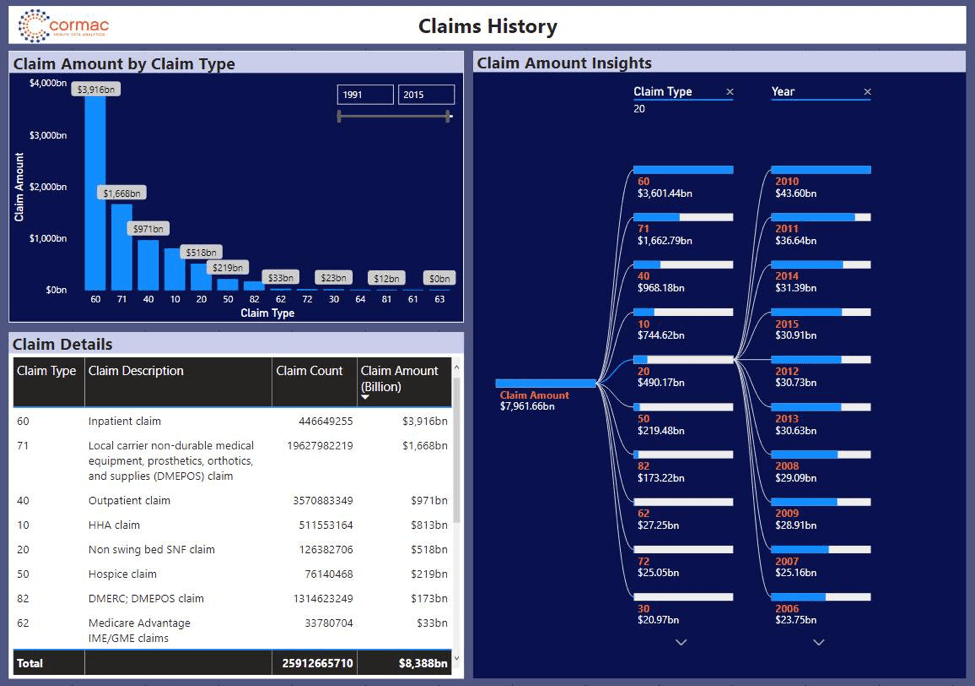
As a next step, a machine learning model can be built to predict and prescribe various business metrics based on the needs. Some examples are:
- Medicare Cost Predictions at the patient or provider level
- Identification of At-Risk Populations
- Reduction of cost, disease burden, and fatalities through preventive measures
- Improper payments FWA Trends